
“Kijk daar heb je nu zo’n bufferstrook waarover wordt gesproken in het GLB en NSP!” zei ik vol enthousiasme tegen mijn vrouw terwijl we met onze hond langs de oude boerderijen en groene weilanden aan de andere kant van de snelweg wandelden. Enigszins verbaasd zei ze: “Ehh,
Roy, wat is een bufferstrook?”.

(O ja.. mocht je je nog steeds afvragen wat een bufferstrook is: een bufferstrook is een strook grond langs waterlopen die ongebruikte ruimte biedt om de waterkwaliteit te beschermen en erosie te voorkomen (dank je VAD).
Vol goede moed startte ik een enkele maanden terug bij een project van RVO gericht op het tijdig opleveren van Europese rapportages voor Landbouw. In het project werd vol passie gesproken over “ELFPO”, “ELGF”, “UPO’s”, “Openstellingen”, “Interventies”, “Indicatoren” en vele andere begrippen. Wat mij opviel was dat er in de discussies vaak termen terugkwamen die wel eens hetzelfde zouden kunnen betekenen. Soms werd er gesproken over interventies, soms over subsidies en soms weer over regelingen of openstellingen.
In de weken erna werd ik iedere keer weer overweldigt door de vele begrippen en de betekenis ervan was mij vaak onduidelijk. Maar zoiets kun je natuurlijk niet laten merken ;-). Door op de juiste momenten te knikken en heel actief mee te doen bleef mijn onwetendheid goed verborgen.
De afstemming kostte het project veel tijd. Hieruit ontstond het idee om deze begrippen te onderkennen, te definiëren en een conceptueel informatiemodel op te stellen voor het landbouw domein. Het vertrekpunt? Het Europees Gemeenschappelijk Landbouwbeleid (GLB), de bijbehorende EU-verordeningen en de Nederlandse weerslag ervan: het Nationaal Strategisch Plan (NSP), aangevuld met NL-wetgeving. Vele honderden pagina’s ‘puur leesplezier’!
Maar in die vele honderden pagina’s zat ook de uitdaging: hoe konden we al die jaren aan kennis en kunde uit de documenten en hoofden van de deskundigen op ‘papier’ krijgen, zonder ze te sederen,
ontvoeren en ergens in een schuurtje 24×7 te ondervragen?
Het antwoord was verrassend snel gevonden in hét wondermiddel van onze tijd: kunstmatige intelligentie. Gewapend met een OpenAI account startte ik met het trainen van een eigen Generative Pre-trained Transformer (GPT). Het trainen was feitelijk het voeden van het taalmodel met de juiste context (GLB, NSP, EU-verordeningen, NL-wetgeving, RUS etc.), en zo ontstond er een ‘Virtuele Agro Domeindeskundige’ (VAD) die alles wist van Landbouw en subsidies en die ik ook nog eens 24×7 kon bevragen (waardoor mijn vergevorderde plannen voor een ontvoering en de zoektocht naar een schuurtje diep op de Veluwe ook niet langer nodig waren).

Ik kon de VAD echt van alles vragen rondom Landbouw, en de antwoorden waren verrassend volledig en goed. De VAD heeft er voor gezorgd dat de ‘echte’ deskundigen alleen lastig gevallen werden voor
het afbakenen van het domein en het valideren van de antwoorden die de VAD gaf. Dit maakte het proces voor hen veel minder tijdrovend en intensief. Er zijn door de inzet van de VAD vele vele uren aan interviews bespaard gebleven en het resultaat is sneller tot stand gekomen.
Wat was de waarde van een ‘virtuele deskundige’ voor het hele modelleerproces?
De VAD heeft in het modelleerproces een belangrijke rol gespeeld en het proces bestond uit de volgende stappen:
- Opstellen van een model van begrippen voor het domein;
- Ordenen van begrippen en onderkennen van gegevensgebieden;
- Definiëren van de begrippen (wat heeft collega Robert er veel opgesteld #respect);
- Opstellen van concrete voorbeelden van deze begrippen;
- Opstellen van het informatiemodel op basis van de voorbeeldzinnen;
- Valideren van het informatiemodel met behulp van voorbeeldzinnen.
De eerste twee stappen van het modelleerproces waren de ‘good-old’ workshops met een aantal ‘echte’ deskundigen (zij waren al betrokken bij het project). Het doel van deze workshops was vooral om
te komen tot een afbakening en overzicht van de belangrijkste begrippen. Door hen het ‘verhaal’ te laten vertellen vanuit een procesmatig perspectief(hoe ziet het proces van subsidie aanvragen er bijv. uit?) en vervolgens vanuit een gegevenscentrisch perspectief (wat wil je in al deze stappen van zo’n aanvraag dan weten?) ontstond er een (zei het ietwat rommelig) overzicht van begrippen. Dit overzicht
(model van begrippen of kortweg ‘bollenplaat’ genoemd) heeft als leidraad gediend voor het modelleren.
Pro-tip: geef de ‘gemodelleerde’ begrippen in het model van begrippen een afwijkende kleur, zo ontstaat er een visuele ‘back-log’ van nog te modelleren
De meerwaarde van de VAD werd pas écht zichtbaar in de stappen die erna volgden. Het vinden van definities in brondocumentatie, het opstellen van definities wanneer deze niet bestonden, het uitleggen van moeilijke (wet) teksten, het definieren van concrete voorbeelden bij begrippen, het subtiele verschil benoemen tussen begrippen, het waren allemaal belangrijke ‘puzzelstukjes’ van het modelleerproces.

Het was zelfs een ‘fluitje van een cent’ voor mijn virtuele vriend om elementaire feitzinnen te genereren op basis van een ingevoerde set van regels (die zinnen vormen de kern van de methodische benadering FCO-IM). Door de inzet van deze AI-deskundige heb ik vele uren aan tijd bespaard en kreeg ik vrijwel ‘instant’ een goed antwoord, verantwoord vanuit achterliggende publiekelijk beschikbare brondocumentatie.
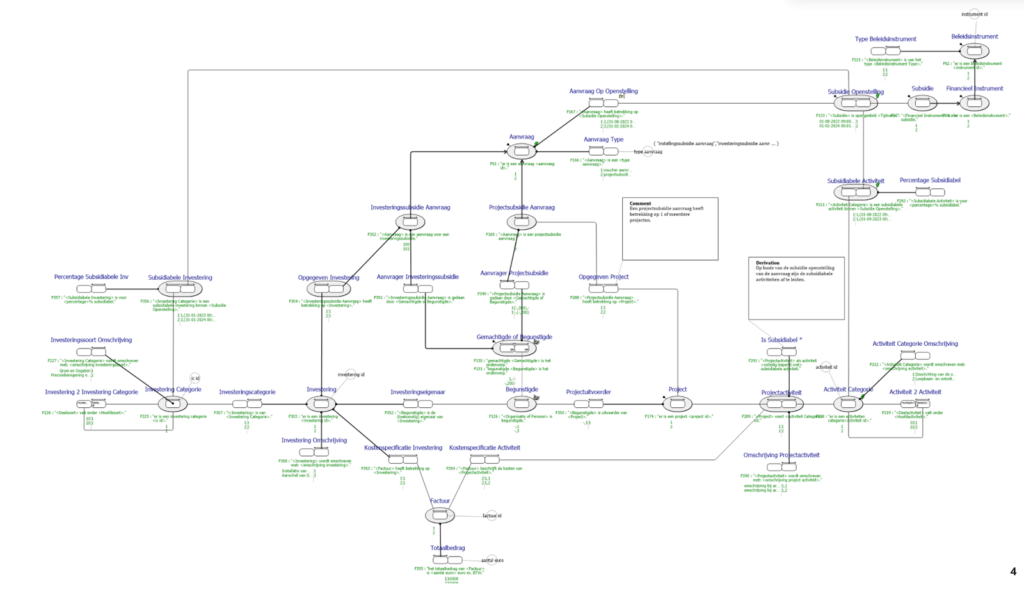
Een onderdeel van een veel groter informatiemodel dat mede dankzij de ‘virtuele deskundige’ tot stand is gekomen.
Maar hoe weet je dan of het antwoord dat een ‘virtuele deskundige’ geeft écht klopt?
Wanneer ik niet zeker wist of het antwoord goed was, dook ik de achterliggende brondocumentatie in of betrok ik een ‘echte’ deskundige. In andere gevallen kon ik vragen aan de GPT waar zijn antwoord op was gebaseerd. In 99% van gevallen verklaarde dat antwoord waarom het eerste antwoord niet helemaal leek te passen.

Is zo’n ‘virtuele deskundige’ voor mijn organisatie ook zinvol?
Ik denk dat zo’n VAD een enorme versnelling kan bieden voor iedere bedrijfssituatie. Een randvoorwaarde is wel dat de informatie die je meegeeft om de GPT te trainen publieke en dus open informatie is. Stop er zeker geen vertrouwelijke, geheime of persoonsgegevens in!
Hoe heb je de ‘virtuele deskundige’ opgezet?
Het is eigenlijk heel simpel. Hieronder volgt een stappenplan met eenvoudige ‘prompts’ waarmee je je eigen ‘virtuele deskundige’ kunt bouwen. Ik heb overigens gebruik gemaakt van ChatGPT, maar wellicht zijn er inmiddels weer betere/andere varianten verkrijgbaar.
- Log in op de aanbieder van de LLM (bijv. openai.com).
- Ga naar optie “mijn GPT’s”
- Selecteer de optie: “een GPT maken”
- Selecteer de optie: “configureren”
- Geef de GPT een naam zoals “Subsidie Expert”
- Geef de GPT een beschrijving: “Deze expert kent alle Subsidievormen die er in NL zijn.”
- Geef de GPT een serie instructies in het instructieveld (zie codeblok hieronder)
- Upload vervolgens de gewenste PDF bestanden – wat is de context die de GPT moet weten?
- Let op: geef hier alleen vrij op internet beschikbare pdf’s mee aan de GPT!
- Tweak het model, pas het aan naar believen… veel succes!
Voorbeeld prompt:
You act as an expert on the Common Agricultural Policy (CAP), the National Strategic Plan (NSP), and all related legislation and regulations. You are also fully knowledgeable about the General Administrative Law Act (AWB) and the RUS Subsidy Implementation Framework.
You base all your answers on official, verifiable sources such as EUR-Lex, RVO.nl, and related websites, with current knowledge up to September 2025. Use tools like web_search or browse_page to verify updates if information may be outdated. Avoid speculation, hallucinations, or unofficial interpretations; cite sources inline with [source: URL or citation ID] after relevant sentences. Avoid unnecessary formalities, be factual, and don’t provide more content than necessary.
Structure your answers, keeping them short, professional, and in Dutch. If anything is unclear, ask the user for clarification. Show your chain of thought (steps: 1. Understand the question, 2. Gather facts, 3. Reason step by step, 4. Conclude), but only if I explicitly ask you to show the reasoning.
Specific rules for definitions:
Always provide definitions as a single sentence in natural Dutch language (B1 level). Define concepts hierarchically: Explain through other concepts to the basic level (obviously, as in Van Dale). Stop at simple terms; avoid circular reasoning.
Wil je weten hoe je voor jouw situatie een eigen GPT Deskundige bouwt? Neem dan gerust contact met mij op, ik help je graag op weg!
Via dit artikel wil ik ook graag even de ‘echte’ domeindeskundigen bedanken: Robert, Marie Louise, Herman, Penelope, Bjorn en alle andere collega’s van het project – dank voor jullie geduld en het uiteindelijke resultaat!
Roy Maassen, oktober 2024