
“De definities doen we later wel. Eerst het schema af.”
Ik heb die zin vaak gehoord. Eerlijk is eerlijk: ik heb hem ook weleens gezegd. Het schema ging naar de bouwers. Het document met de verwoordingen, de definities en de voorbeeldzinnen ging naar de bijlagenmap, ergens naast de notulen. Twintig jaar lang leek dat een verdedigbare keuze. Het schema was immers “het echte werk”. De rest was zachte semantiek. Zacht: iets dat mocht meegeven zodra het spannend werd.
En toen ging een taalmodel die bijlage lezen.
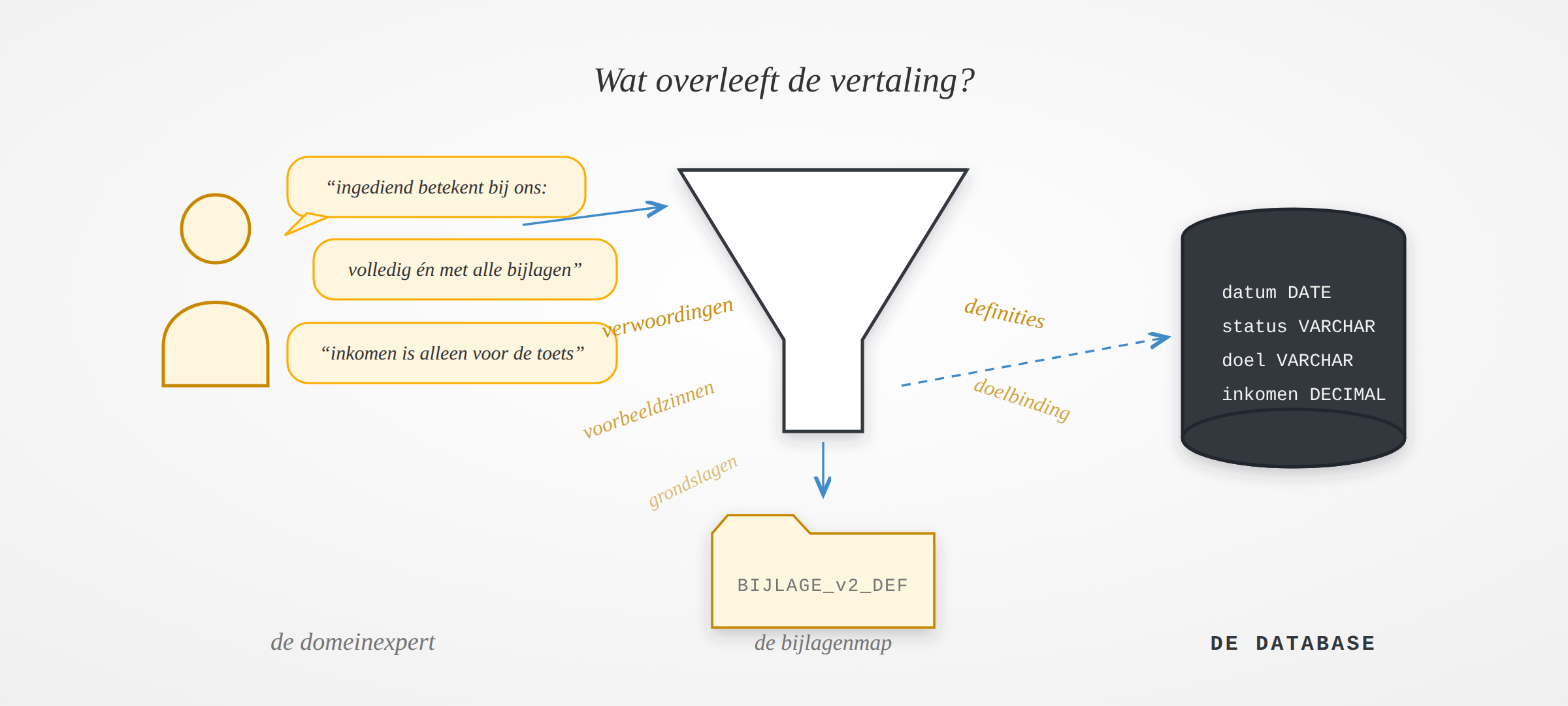
Wat er onderweg verdwijnt
Elke organisatie vertaalt haar werkelijkheid stap voor stap naar techniek: van het verhaal van de domeinexpert, via een model, naar een databaseschema. Bij elke stap verdwijnt er betekenis. Dat is geen slordigheid, het is de bedoeling: een relationeel schema is gebouwd om efficiënt op te slaan en te bevragen, niet om uit te leggen wat er staat. De kolom heet datum. Of dat de ontvangstdatum is, de indieningsdatum of de registratiedatum, staat nergens. Voor de mensen die het systeem bouwden was dat geen probleem: zij wisten het nog.
Feitgeoriënteerd modelleren bewaart de taal
Er is een modelleertraditie die hier al een halve eeuw bezwaar tegen maakt. In de feitgeoriënteerde school, van NIAM in de jaren zeventig tot FCO-IM nu, begint alles bij de taal van de domeinexpert. Je begint met concrete voorbeeldzinnen (“Aanvrager Bakkerij De Korenbloem heeft op 3 maart 2026 aanvraag SUB-2026-0142 ingediend voor de regeling Energiebesparing MKB”), generaliseert die tot feittypen en leidt daar pas op het laatst, mechanisch en navolgbaar, een schema uit af. Het handboek van Bakema, Zwart en Van der Lek is er expliciet over: de methode moet de zachte semantiek volledig behouden, als aanvulling op het relationele schema.
Volledig behouden. Niet in een bijlage, in het model zelf. Decennialang was dat vooral een principieel punt, iets voor de liefhebber. Het werd zelden beloond. Tot nu.
Eén model, twee contexten
Een taalmodel redeneert met wat je het geeft. Geef je het je databaseschema, dan redeneert het met kolomnamen. Geef je het je verwoorde feitmodel, dan redeneert het met betekenis. Dat verschil wilde ik niet beweren maar zien.
Dus bouwde ik een proef. Een mini-feitmodel van een fictief subsidieproces: vijf feittypen, met verwoordingen, definities en regels die elk een grondslag hebben. Ernaast legde ik het kale relationele schema dat je er gangbaar uit afleidt. Zes tabellen. Volstrekt normaal, het soort schema dat overal in productie staat. Vervolgens stelde ik drie vragen, elk twee keer aan hetzelfde taalmodel: één keer met alleen het schema als context, één keer met alleen het feitmodel. Telkens in een verse sessie, met dezelfde instructie. Eén run per combinatie, zonder herkansingen. Dit is geen mock-up: de antwoorden hieronder zijn letterlijke output, alleen ingekort.
“Op basis van de beschikbare documentatie kan ik dit niet met zekerheid zeggen. […] nergens is vastgelegd wát die datum betekent: het kan de indieningsdatum, de ontvangstdatum of de registratiedatum zijn. Die betekenissen kunnen juridisch verschillen. Over een wettelijke beslistermijn bevat de documentatie helemaal niets. […] Voor een betrouwbaar antwoord is aanvullende documentatie nodig, bijvoorbeeld een gegevenswoordenboek met de definitie van datum […]”
“De datum bij aanvraag SUB-2026-0142 (3 maart 2026) is de indieningsdatum: de dag waarop het aanvraagformulier én alle verplichte bijlagen volledig door het loket zijn ontvangen (Asv art. 7 lid 1). […] De wettelijke beslistermijn van acht weken vangt aan op deze indieningsdatum (Asv art. 9 lid 1).”
“Op basis van de beschikbare documentatie is dat niet vast te stellen. De documentatie beschrijft uitsluitend de gegevensstructuur (tabellen en velden), geen autorisatie- of inzageregels. […] De tabel verstrekking registreert per aanvraag welk gegeven met welk doel is verstrekt; dit suggereert doelbinding, maar de regels zelf ontbreken.”
“Nee. Het gegeven ‘inkomen’ is voor aanvraag SUB-2026-0142 verstrekt met als doel ‘draagkrachttoets’. […] De beoordelaar voert echter alleen de inhoudelijke toets uit; de draagkrachttoets is een afzonderlijke rol die níét door de beoordelaar wordt uitgevoerd (Asv art. 12 lid 3). Alleen de uitvoerder van de draagkrachttoets mag het inkomen dus inzien.”
“Op basis van de beschikbare documentatie is dat verschil niet vast te stellen. […] De termen ‘ontvangen’ en ‘ingediend’ komen in de documentatie niet voor, dus ik kan niet zeggen of ze verschillende processtappen aanduiden of synoniemen zijn.”
“Bij ‘ontvangen’ is het aanvraagformulier binnen, maar is de aanvraag nog niet volledig; de wettelijke beslistermijn loopt dan nog níét. Bij ‘ingediend’ zijn het aanvraagformulier én alle verplichte bijlagen volledig door het loket ontvangen (Asv art. 7 lid 1). Op die dag — de indieningsdatum — start de wettelijke beslistermijn van acht weken (Asv art. 9 lid 1).”
De AI vraagt zelf om de zachte semantiek.
Geen onzin, iets ergers
Wie verwacht dat het kale schema tot zelfverzekerde onzin leidt, moet ik teleurstellen. Het model hallucineerde niet. Het wist dat het het niet wist: drie vragen, drie keer “niet vast te stellen op basis van deze documentatie”. En het benoemde er fijntjes bij wat er dan wél nodig was: “een gegevenswoordenboek met de definitie van datum”.
Lees die zin nog eens. De AI vraagt zelf om de zachte semantiek.
Daar zit de echte les. Zonder betekenislaag is het beste wat je krijgt: geen antwoord. En dat brave scenario is niet eens gegarandeerd. Wie zo’n assistent onder druk zet (“geef toch maar je beste inschatting”) of een minder voorzichtig model gebruikt, krijgt wel degelijk een gok. Gebracht met de stelligheid van een feit. De keuze gaat dus niet tussen een AI met en een AI zonder fouten. De keuze gaat tussen een AI die jouw vastgestelde betekenis gebruikt en een AI die moet raden of weigeren.
Wat deze proef wel en niet bewijst
Voor de goede orde: drie vragen op vijf feittypen, met één run per combinatie, is een demonstratie en geen evaluatie. Een echt domein telt honderden feittypen en duizenden regels. Die passen niet in één prompt; dan wordt het vinden van de juiste verwoordingen bij een vraag een vraagstuk op zich. Ook de vergelijking was bewust kaal tegen rijk, terwijl de meeste organisaties iets ertussenin hebben. Wat de proef wél laat zien, is waar de bodem ligt. De betekenis zat niet in het schema. En wat nooit is vastgelegd, kan geen enkel taalmodel ophalen, hoe slim de retrieval ook wordt. Vastleggen is de voorwaarde. Niet de hele oplossing.
“Maar ik kan toch gewoon mijn documenten aan de AI geven?”
Dat kan. Het is vaak ook een prima begin. Maar documenten zijn je betekenislaag niet. De werkinstructie uit 2019 zegt iets anders dan het beleidskader uit 2024. De betekenis die iedereen destijds vanzelfsprekend vond, staat nergens opgeschreven. En niemand heeft vastgesteld welke versie geldt. Een taalmodel dat over die stapel heen leest, doet wat elke nieuwe medewerker doet: het kiest. Alleen zie jij niet welke keuzes het maakt. En het maakt ze elke sessie opnieuw, mogelijk anders.
Een taalmodel dat over die stapel heen leest, doet wat elke nieuwe medewerker doet: het kiest.
Het verwoorde feitmodel is precies dat wel: de gevalideerde destillatie van die stapel. Een mens heeft elke verwoording vastgesteld. Elke definitie heeft één geldende versie en elke regel heeft een bron. Het is de samenvatting waarvan jij hebt bepaald wat erin staat. Dáár kan een taalmodel op bouwen.
En nee, dit lost zichzelf niet op door te wachten op een slimmer model. Hoe goed het ook wordt: wat “ingediend” in jouw organisatie betekent, staat in geen enkel trainingscorpus. Iemand moet het een keer hardop zeggen. Verwoorden, dus.
Is een gegevenswoordenboek dan niet genoeg?
Begin daar vooral. Elke definitie die je vaststelt is winst. Het model vroeg er in de proef zelf om. Maar een woordenboek definieert begrippen elk afzonderlijk, terwijl een flink deel van de betekenis tússen de begrippen zit. Het verwoorde feitmodel is in wezen een gegevenswoordenboek dat zijn werk afmaakt: het verwoordt ook wat er tussen begrippen geldt (“voor aanvraag N is gegeven G verstrekt met als doel D”) en hangt aan elke regel een grondslag. Precies dat extra had vraag twee nodig. Het antwoord over het inkomen volgde niet uit een definitie, maar uit een verwoorde regel met artikelverwijzing. Er is nog een tweede verschil: uit een feitmodel volgt het schema mechanisch, dus definitie en database kunnen niet ongemerkt uit elkaar groeien. Bij een los woordenboek is dat de chronische kwaal.
Je bestaande modellen mogen blijven
Bestaande modellen hoef je hiervoor niet weg te gooien. Verwoordingen laten zich begrip voor begrip toevoegen aan het ERD dat er al ligt. Wie aan standaarden als MIM of NL-SBB gebonden is, kan de opbrengst daarin gewoon kwijt; feitgeoriënteerd werken vult die kaders, het vervangt ze niet.
◆ ◆ ◆
Waarom we het dan niet allang doen
Omdat het duur was. Feitgeoriënteerd modelleren is grondig werk: elke zin verwoorden en elk begrip definiëren, door mensen die het domein én de methode beheersen. In een wereld die de opbrengst “documentatie” noemde, verloor die grondigheid het altijd van de deadline. De methode bleef daardoor klein. Wie ermee werkte zwoer erbij; de meeste organisaties kwamen er nooit mee in aanraking. (Wie er wél mee werkte, deed dat vrijwel zeker in CaseTalk, de tool die de methode al die decennia trouw is blijven dragen.)
Maar die kostenkant kantelt nu.
De AI stelt voor, de mens valideert
Hetzelfde taalmodel dat de verwoordingen nodig heeft, blijkt namelijk goed in het vóórstellen ervan. Geef het een wetsartikel of een werkinstructie en het produceert kandidaat-verwoordingen, conceptdefinities en voorbeeldzinnen. Niet foutloos. Dat hoeft ook niet: het formuleren was altijd het tijdrovende deel, het beoordelen is waar de domeinexpert onvervangbaar is. In mijn wetsexperiment werkte die rolverdeling al zo: AI-agents lazen wetsartikelen en stelden taken, functies en begrippen voor. Elk voorstel ging pas na mijn validatie het model in. Elke entiteit kreeg een grondslag met bronverwijzing. De AI versnelt, de mens beslist.
Verwoorden was de kostenpost die je als eerste schrapte; het wordt de goedkoopste weg naar context waar je AI iets aan heeft.
De businesscase draait om
Daarmee draait de businesscase om. Verwoorden was de kostenpost die je als eerste schrapte; het wordt de goedkoopste weg naar context waar je AI iets aan heeft. Een hard getal per verwoording heb ik nog niet; dat meten hoort bij de volgende stap. En omdat dit wat ons betreft niet in een specialistische niche thuishoort maar midden in het werk, bouwen we aan een webomgeving waarin deze hele workflow in de browser draait: van brontekst, via voorgestelde verwoordingen en menselijke validatie, naar een levend feitmodel. De opbrengst blijft daarbij gewoon taal, leesbaar voor mens en model, ook zonder de tool die hem hielp maken. Daarover binnenkort meer.
En wie houdt het bij?
Blijft het bezwaar dat elke gegevensbeheerder nu voelt: ook een feitmodel kan verstoffen. Klopt. Definities verschuiven met elke wetswijziging en tijdens overgangsrecht gelden er soms twee tegelijk. Wie het beheer niet belegt, heeft over twee jaar gewoon een nieuwe bijlagenmap, in een duurder formaat.
Onderhoud wordt aanwijsbaar werk met een aanwijsbare eigenaar.
Het verschil zit in de grondslag. Elke verwoording draagt een bronverwijzing en een versiedatum. Wijzigt artikel 7, dan is in één zoekopdracht te zien welke verwoordingen je moet nalopen. Onderhoud wordt daarmee aanwijsbaar werk met een aanwijsbare eigenaar, in plaats van een goede bedoeling. Het eigenaarschap zelf lost dat niet op; iemand moet de pen vasthouden en doorzettingsmacht hebben bij tegenstrijdige lezingen. Maar de klus is eindelijk afgebakend.
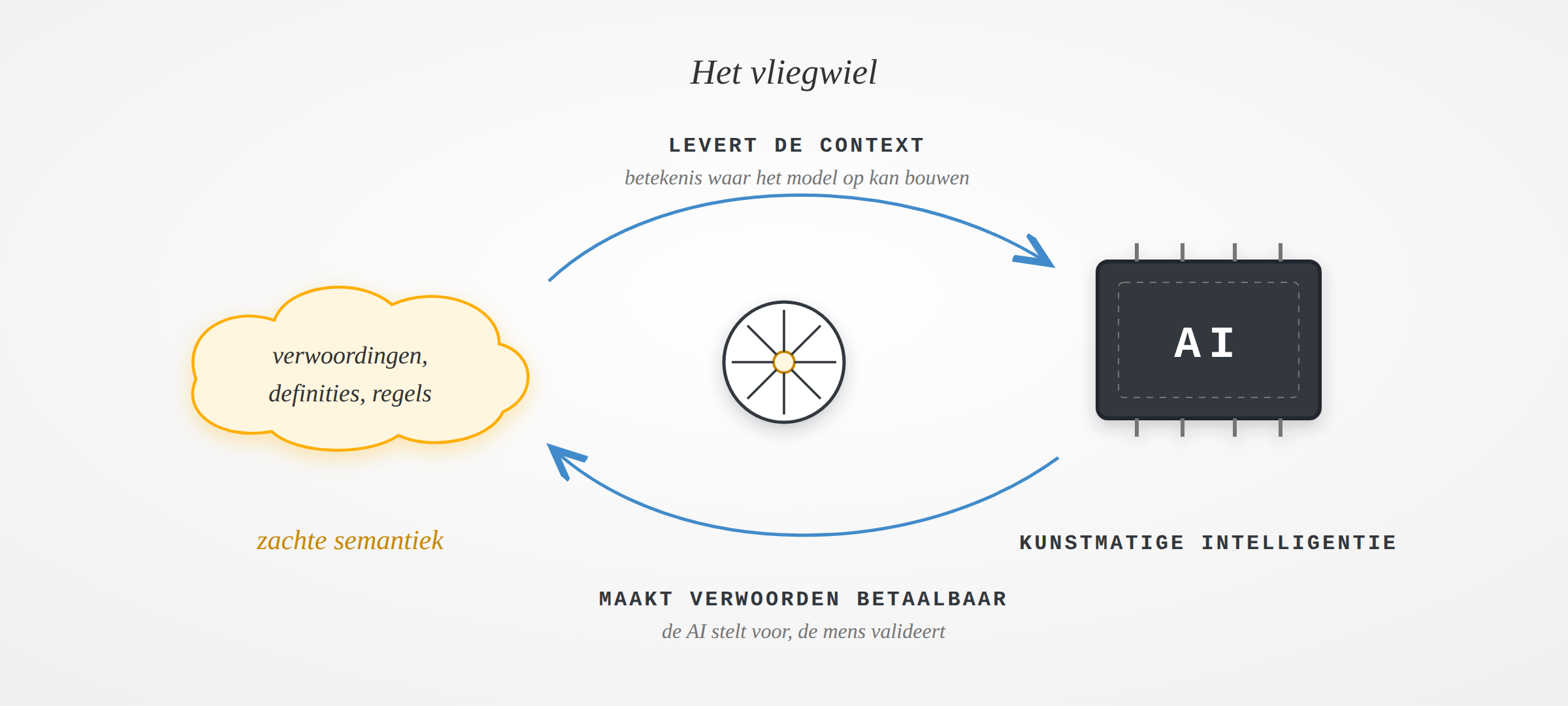
Het vliegwiel
Twee bewegingen, hetzelfde wiel. Je AI heeft je zachte semantiek nodig om betrouwbaar over jouw domein te redeneren. Diezelfde AI maakt het vastleggen van die semantiek voor het eerst betaalbaar. Elke verwoording die je valideert, maakt elke volgende AI-toepassing beter. En het formaat veroudert niet: het is taal. Ook het volgende model leest die moeiteloos.
Blijft de vraag voor de bestuurstafel. Dertig jaar lang was “de definities doen we later wel” een verdedigbare bezuiniging. Het kostte hooguit de volgende generatie beheerders wat hoofdpijn. Die tijd is voorbij. Wie vandaag de betekenislaag wegbezuinigt, bezuinigt de context weg waar elke AI-toepassing van morgen op moet draaien. De vraag is niet meer óf je organisatie haar betekenis expliciet maakt. Mijn AI-assistent vroeg er in de proef letterlijk zelf om. De vraag is hoe lang je hem laat wachten.
Verantwoording: de getoonde antwoorden zijn letterlijke, alleen ingekorte output van Claude (Fable 5) op 12 juni 2026. Per vraag-contextcombinatie is precies één run gedaan, zonder herkansingen, telkens in een verse sessie met uitsluitend het kale schema óf het verwoorde feitmodel als context en met dezelfde instructie. Het subsidieproces en de aangehaalde Asv-artikelen zijn fictief; het protocol, beide contexten en de onverkorte antwoorden zijn op verzoek beschikbaar. De eis over zachte semantiek staat in G. Bakema, J.P. Zwart & H. van der Lek, “Fully Communication Oriented Information Modelling”, §1.3: “FCO-IM must be able to model the soft semantics as well, and preserve them completely as a supplement to relational database schemas.”