
De vraag
De keuze die voorligt
Een relatie legde ons onlangs een keuze voor in een tooltraject voor gegevensmodellering. De wens is een simpele en breed toegankelijke tool, die van conceptueel tot fysiek modelleert, de volledige verticale herkomstketen (lineage) borgt, bidirectioneel koppelt met de catalogus en enkele lichte controles toelaat. Daar hoort een stellige keuze bij: haal het transformeren uit de modelleertool. De modelleur doet conceptueel tot fysiek en genereert de DDL (de definitietaal waarmee we fysieke databasestructuren vastleggen). De bron-doelmapping (het uitlezen, bewerken en wegschrijven van gegevens van bron naar doel, de ETL) gaat volledig naar de transformatielaag, met de controles in de CI/CD (de geautomatiseerde bouw- en teststraat).
Twee vragen, het antwoord aan het eind
Twee vragen liggen voor. De eerste: houden we het modelleren en het transformeren in één rol en één tool, of scheiden we die twee? De tweede: als we scheiden, hoe zuiver doen we dat, met het risico dat het model en de bouw uit elkaar groeien? We zoeken het antwoord langs vier lijnen: het ontwerpprincipe, de aanpak bij onderdelen van de overheid, de gangbare praktijk in het bedrijfsleven en de bezwaren van de modelleur, de engineer en de leverancier. Aan het eind van dit stuk geven we ons antwoord.
We bouwen voort op een principe dat al vijftig jaar staat

Separation of concerns is geen mode
Het scheiden van betekenis en techniek heet in de informatica separation of concerns. Edsger Dijkstra introduceerde de term in 1974 en noemde die “the only available technique for effective ordering of one’s thoughts, that I know of” (E.W. Dijkstra, On the role of scientific thought, EWD447, 1974). We bestuderen een aspect in isolatie, in het besef dat we ons met maar één aspect bezighouden. De betekenis van gegevens is zo’n aspect, de technische verplaatsing een ander.
De drie-schema-architectuur scheidt betekenis van opslag
In het vakgebied gegevens kreeg dit principe in 1975 een vaste vorm met de drie-schema-architectuur van ANSI/SPARC: een extern schema (de gebruikersbeelden), een conceptueel schema (de betekenis) en een intern schema (de fysieke opslag). De betekenis staat los van de opslag. Betekenis en opslag staan allebei los van de toepassing.
Wie de techniek vóór de betekenis zet, modelleert het verkeerde
William Kent maakte in Data and Reality (oorspronkelijk 1978, tweede editie 2000) scherp waarom dat onderscheid ertoe doet. Kent stelt dat een informatiesysteem niet de werkelijkheid is, maar een afbeelding ervan: “An information system (e.g., database) is a model of a small, finite subset of the real world” (Kent, Data and Reality, hoofdstuk 1, p. 1). Wie de techniek vóór de betekenis zet, modelleert het verkeerde. Kent waarschuwt daar expliciet voor in zijn paragraaf over modellen van de werkelijkheid tegenover modellen van gegevens: “One thing we ought to have clear in our minds at the outset of a modeling endeavor is whether we are intent on describing a portion of ‘reality’ (some human enterprise), or a data processing activity. Most models describe data processing activities, not human enterprises” (Kent, Data and Reality, paragraaf 7.3, p. 111). De oorzaak die Kent noemt is precies de rolvermenging: zodra het vocabulaire van de gegevensverwerking (velden, records, waarden) het model binnenkomt, beschrijven we de techniek en niet langer de werkelijkheid.
Betekenis eerst, representatie daarna
Kent verbindt deze scheiding ook aan een rol. Hij beschrijft de opkomende databasebeheerder, die de informatie eerst zuiver beschrijft in termen van betekenis (het conceptuele model) en pas daarna de externe en interne modellen vastlegt: met dat conceptuele model als referentie “he can then separately specify the various formats in which this data is to be made available to application processes (the external models), and also the physical organizations in which the data is to exist in the machine (the internal model)” (Kent, Data and Reality, paragraaf 2.2.2, p. 30). En in zijn paragraaf over het scheiden van symbolen en dingen vat Kent de winst samen als onafhankelijkheid van de techniek: we verschuiven de verantwoordelijkheid voor het representeren weg van de tekens; “this shift of responsibility gives us greater freedom” en maakt validatie mogelijk “independent of questions of implementation or internal representation” (Kent, Data and Reality, paragraaf 3.8, p. 64). De modelleur werkt aan betekenis, de engineer aan representatie. De eerste gaat aan de tweede vooraf. Kent vat dat bondig: “Becoming an expert in data structures is like becoming an expert in sentence structure and grammar. It’s not of much value if the thoughts you want to express are all muddled” (Kent, Data and Reality, hoofdstuk 1, p. 2).
Twee assen: modelleren versus verwerken
De moderne data-architectuur maakt dit principe concreet door de concerns langs twee assen te scheiden. De verticale as gaat over definitie en modellering, van lexicaal en ontologisch tot logisch en technisch. De horizontale as gaat over de levenscyclus en de verwerking, van vastleggen en valideren tot integreren, afleiden en uiteindelijk opschonen. De verticale as is het werk van de modelleur, de horizontale as dat van de engineer. Een volwassen data-architectuur houdt bovendien lage technologische intimiteit: een bewuste afstand tot de techniek. De architectuur blijft leverancier- en technologieneutraal.
Onderdelen van de overheid houden het verplaatsen al buiten het model
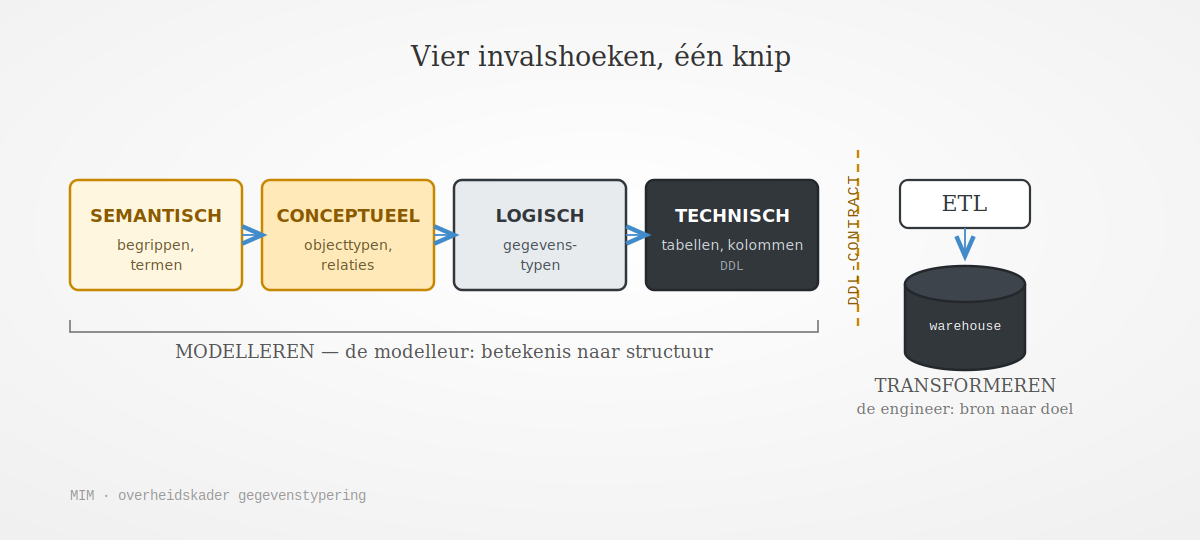
Vier invalshoeken, met MIM als overheidsbrede standaard
Onderdelen van de overheid hebben dit principe concreet gemaakt. In hun aanpak van gegevenstypering modelleren ze de betekenis van gegevens langs vier invalshoeken: een semantische invalshoek (de begrippen en termen), een conceptuele invalshoek (de objecttypen, hun eigenschappen en hun relaties, samen het beschouwingsdomein, oftewel de werkelijkheid), een logische invalshoek (de gegevenstypen binnen het verwerkingsdomein) en een technische invalshoek (de berichten, tabellen, documenten en graphs, oftewel het technische datamodel). Dat is exact de ladder van conceptueel tot fysiek die de relatie in de tool wil. Het Metamodel Informatiemodellering (MIM) is wél een overheidsbrede standaard, beheerd door Geonovum en geborgd via Forum Standaardisatie. MIM onderbouwt deze ladder en verbindt via taalbindingen met UML, ERM, Fact-Based Modeling en Linked Data.
De begrippen beginnen bij de wet
De begrippen en definities aan de bovenkant van die ladder komen niet uit de lucht vallen. Voor een organisatie met een wettelijke taak is de wet de bron. We zien wetsanalyse, een initiatief vanuit de overheid, als het startpunt voor de begripsextractie: daarmee halen we de begrippen en definities gestructureerd uit de wet- en regelgeving. De conceptuele modellen haken daarop in, zodat de betekenis herleidbaar blijft tot de bron in de wet. We werkten dat idee eerder uit in De blauwdruk van je organisatie staat gewoon in de wet.
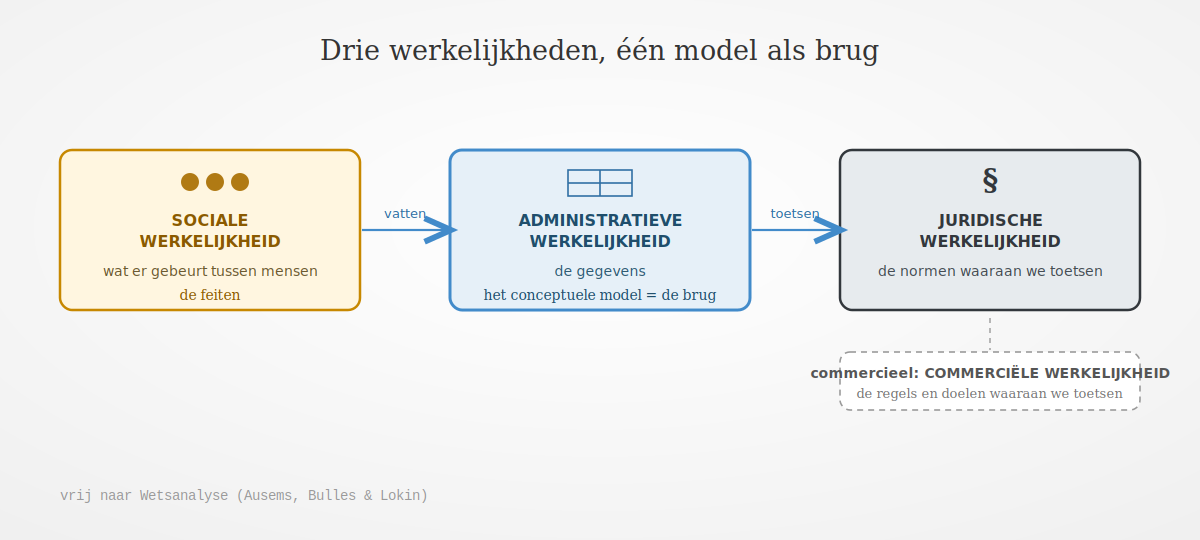
Drie werkelijkheden: sociaal, administratief, juridisch
In het verlengde van wetsanalyse helpt het om drie werkelijkheden te onderscheiden. De sociale werkelijkheid is wat er feitelijk gebeurt tussen mensen. De administratieve werkelijkheid is de verzameling gegevens waarin we die feiten vastleggen. De juridische werkelijkheid is het stelsel van normen waaraan we toetsen. Wetsanalyse koppelt deze lagen: uit de werkelijkheid leiden we de rechtsfeiten af, die we vastleggen als gegevens, om er de rechtsgevolgen aan te verbinden. We vatten de sociale werkelijkheid dus in de administratieve werkelijkheid, om die aan de juridische werkelijkheid te kunnen toetsen. Het conceptuele model is precies die brug: het beschrijft de sociale werkelijkheid in begrippen, zodat de administratie toetsbaar wordt aan de norm.
Commercieel speelt hetzelfde
Het bedrijfsleven kent dit patroon ook, met een commerciële werkelijkheid in plaats van een juridische. We vatten dezelfde sociale werkelijkheid in de administratie, om die te toetsen aan de commerciële regels en doelen. Het verschil zit in de norm waaraan we toetsen, niet in de noodzaak van een zuiver conceptueel model dat de werkelijkheid vasthoudt.
Het zijn geen attributen, het zijn levens
Hier raakt het ons. In de tooltaal heten het attributen en velden. Maar het zijn gegevens die over levens en over de werkelijkheid gaan: over een uitkering die wel of niet komt, over een kind dat wel of niet wordt gezien. Wie de betekenis verwaarloost en alleen de structuur telt, behandelt mensen als records. Dat is precies waarom de modelleur geen technische bijrol heeft, maar de werkelijkheid bewaakt. De scheiding die we bepleiten is geen organisatorische voorkeur, maar een manier om die werkelijkheid recht te doen.
Scheid de kennis van de verwerking
Een verwante gedachte uit de kennisarchitectuur scheidt de kennis van de verwerking. De kennis bestaat uit de begrippen, definities en regels, herleidbaar tot de wet. De verwerking is de logistiek die de gevallen afhandelt. De kennis is het domein van de modelleur, de verwerking dat van de engineer. Wie die twee scheidt, betaalt minder onderhoud en wordt wendbaarder: verandert de wet of een regel, dan passen we het kennismodel aan en volgt de verwerking, in plaats van de systemen opnieuw te bouwen. Ontbreekt de herleidbaarheid naar de bron, dan is de impact van een wetswijziging niet te overzien en wordt de organisatie afhankelijk van schaarse experts.
Het verplaatsen krijgt een eigen instrument
De modelleerketen stopt bij het technische datamodel. Het verplaatsen van gegevens is een aparte laag met een eigen instrument. Bij de aanpak van gegevensdeling krijgt elke levering een eigen leveringsprotocol: per levering een vastgelegd contract, in feite een datacontract. Een datacontract is een afdwingbare afspraak over de vorm en de betekenis van wat we leveren. Het transformeren en leveren blijft zo bewust buiten het model.
De rol is al gesplitst
Diezelfde grens komt terug in de rolverdeling. Onderdelen van de overheid kennen in hun inrichting van gegevensmanagement een aparte gegevensmodelleur, verantwoordelijk voor de conceptuele, logische én technische modellen, niet voor de transformatie. Die inrichting splitst zelfs binnen het modelleren: een kennismodelleur ontwikkelt de begrippen en conceptuele modellen, een gegevensmodelleur werkt die uit in logische en technische modellen. Dat bevestigt dat één persoon die model én verplaatsing doet geen noodzaak is, maar een keuze die we kunnen ontvlechten.
De tool is vrij, de standaard niet
Ook de toegankelijke tool past in dit beeld. Deze aanpak laat elke organisatie zelf de methode en de hulpmiddelen kiezen, maar verplicht de vastgestelde standaarden zodra organisaties de modellen uitwisselen. De governance zit in de standaard en in de uitwisseling, niet in de tool. Dat rechtvaardigt een simpele tool. De aanpak voegt daaraan toe dat we bestaande formele begrippen hergebruiken in plaats van dezelfde wetgeving overal opnieuw te modelleren, wat de toegankelijkheid en het hergebruik via een centrale registratie versterkt.
Het bedrijfsleven doet vaak het tegenovergestelde

De markt voegt de rollen juist samen
De gangbare praktijk in het bedrijfsleven wijkt af van zowel het principe als deze overheidsaanpak. De afgelopen jaren is het modelleren naar de achtergrond verdwenen en heeft het transformeren de leiding genomen. De transformatielaag heeft daar een rol genaamd de analytics engineer omheen gebouwd, die de analist en de engineer juist samenvoegt in plaats van scheidt (State of Analytics Engineering 2024 en 2025, branche-onderzoek). Het modelleren gebeurt dan onderin de transformatielaag, bottom-up, in lagen van ruwe gegevens naar rapportagetabellen (de staging-, intermediate- en mart-modellen), vaak zonder een apart conceptueel of logisch model.
Logisch en fysiek vallen samen, de bekende fout
Het gevolg is een bekende fout. In de transformatiepraktijk vermengen teams de logische structuur met de fysieke configuratie in hetzelfde model, zonder scheiding tussen de twee (Towards Data Science, Data Modeling for Analytics Engineers). Dat is precies de rolvermenging waar Kent voor waarschuwde, nu in moderne gereedschappen. Het voorstel van de relatie is in dat licht niet ouderwets, maar strenger dan de norm: het herstelt de scheiding die de analytics-engineer-beweging heeft opgeheven en staat dichter bij de klassieke discipline en bij deze overheidsaanpak dan bij de huidige hoofdstroom.
Twee krachten trekken aan de keuze
Hier zit de spanning die een tooltraject zelden hardop benoemt. Het gemak trekt naar de ene kant, want het samenvoegen van de rollen is sneller en vraagt alleen SQL. Het principe trekt naar de andere kant, want het scheiden van betekenis en techniek houdt het model waar. De meeste organisaties laten die spanning in het voordeel van het gemak beslechten zonder het te besluiten. Pas wanneer het model en het warehouse uit elkaar zijn gelopen, blijkt de prijs. Dat ongemerkt uiteenlopen van model en werkelijkheid noemen we drift.
Waar het concreet misgaat
Waar dat schuurt, is concreet aan te wijzen. Een begrip krijgt twee definities: de business bedoelt met “klant” iets anders dan de tabel dim_customer in de transformatielaag en dat verschil blijft onzichtbaar tot een rapportage twee getallen oplevert die geen van beide duidelijk fout zijn. Een hernoeming loopt mis: de modelleur legt klant_id vast, een engineer levert onder tijdsdruk customer_id. De herkomstketen in de catalogus knipt vervolgens op die plek doormidden. De vraag die elke stuurgroep stelt, of een cijfer klopt, wordt onbeantwoordbaar zodra de betekenis en de berekening niet aan elkaar vastzitten, want dan is niet te zeggen of een afwijking een definitiekwestie is of een fout in de transformatie.
De markt corrigeert met datacontracten
De hoofdstroom corrigeert zichzelf inmiddels op het punt dat ertoe doet. Sinds 2023 kennen moderne transformatieframeworks schemacontracten, die het schema van een model bij het bouwen afdwingen en de build laten falen zodra de uitkomst afwijkt van het afgesproken contract. Dat is exact het instrument waarmee we de scheiding tussen modelleur en engineer veilig maken.
We beantwoorden de zorgen van de modelleur
Zorg 1: raak ik los van de productie?
De modelleur stelt een terechte vraag: raak ik niet losgekoppeld van wat er in productie echt gebouwd wordt zodra ik de transformatie loslaat? Dat risico bestaat. Onderdelen van de overheid beleggen die zorg expliciet bij de gegevensmodelleur, die de inconsistenties tussen de modellen en de implementatie signaleert. We lossen het op door het fysieke model een datacontract te maken dat de CI/CD toetst. Een afwijking tussen het gemodelleerde fysieke model en de gebouwde structuur geeft een rode build, een blokkerende foutmelding in plaats van een document dat niemand leest. Zo houdt de modelleur de verbinding met de implementatie zonder de transformatie zelf te bouwen.
Zorg 2: wie is verantwoordelijk voor de fysieke structuur?
Een tweede vraag gaat over verantwoordelijkheid: wie is verantwoordelijk voor de fysieke structuur, de modelleur of de transformatielaag? De modelleur genereert de DDL uit het fysieke model, want het technische datamodel hoort bij de modelleerrol. Daarna vult en transformeert de transformatielaag bínnen die structuur. De modelleur is verantwoordelijk voor de structuur, de engineer voor de vulling. Het datacontract bewaakt de grens.
Zorg 3: verlies ik mijn checks?
De derde vraag betreft de controles: verlies ik mijn checks in een simpele tool? Dat hoeft niet, mits we de controles verdelen. De structuur- en semantiekcontroles (naamgeving, datatypen, verplichte eigenschappen, hergebruik van begrippen) horen in de modelleertool. De gegevenskwaliteit en de transformatiecorrectheid horen in de transformatielaag en de CI/CD. De conceptuele invalshoek is bovendien de hefboom voor toegankelijkheid: die invalshoek beschrijft het beschouwingsdomein, de werkelijkheid waar de business over meepraat. Een tool die op dat niveau leesbaar is, neemt de business mee zonder dat de modelleur naar de techniek hoeft af te dalen.
We beantwoorden de zorgen van de gegevensengineer
Zorg 1: word ik geblokkeerd?
De engineer vraagt zich af of de scheiding hem niet blokkeert: elke modelwijziging betekent dan wachten op de modelleur. De grens is een contract, geen loket. De modelleur levert de DDL en het schema als een versiebeheerd artefact. De engineer bouwt daartegen in de transformatielaag. Een wijziging loopt via het contract en de CI/CD, niet via een ticket. Dat is sneller dan de huidige situatie, waarin één persoon model én transformatie doet en daarmee zelf de bottleneck vormt.
Zorg 2: krijg ik end-to-end herkomst?
De engineer stelt vervolgens de scherpste vraag: krijg ik end-to-end herkomst of een gat op de naad? Er zijn twee soorten lineage. De verticale lineage (van conceptueel tot fysiek) ontstaat in de modelleertool. De horizontale lineage (van bron naar doel) ontstaat in de transformatielaag. Beide moeten samenkomen in de catalogus, bidirectioneel: het model gaat erin, de lineage-metadata van de transformatielaag gaat erin. Gebeurt dat niet, dan ontstaat een herkomstgat op precies de naad die we net hebben gemaakt. Wij adviseren om de bidirectionele koppeling met de catalogus in een proof of concept te toetsen, want “native bidirectioneel” is een claim van de leverancier en geen vaststaand feit.
Zorg 3: is centraliseren wel de bedoeling?
De laatste vraag raakt het paradigma: de transformatielaag centraliseert en transformeert, is dat wel de bedoeling? Dit is de belangrijkste correctie. Deze overheidsaanpak minimaliseert juist het verplaatsen. De levering loopt via een leveringsprotocol en de gegevens worden bij de bron bevraagd in plaats van gekopieerd. De transformatielaag hoort daarom in het analytische vlak (het datawarehouse en de rapportages). Voor operationele uitwisseling federeren we via gestandaardiseerde leveringen in plaats van nog een kopie te bouwen. We scopen de transformatielaag dus bewust tot de analytische laag.
We beantwoorden de bezwaren van de leverancier
De leverancier brengt drie bezwaren in
De leverancier van een geïntegreerde modelleertool heeft een commercieel belang bij het tegendeel en brengt drie bezwaren in die we serieus nemen.
Bezwaar 1: waarom twee tools?
Het eerste bezwaar gaat over de twee gereedschappen: waarom een aparte modelleertool en de transformatielaag, met twee licenties en een naad die je zelf bouwt, terwijl één tool het modelleren én de transformatie doet? Omdat de geïntegreerde tool precies de vermenging in de hand werkt die we willen vermijden. De logische structuur valt samen met de fysieke en het model wordt onleesbaar voor wie de tool niet heeft. De naad die we zelf bouwen is een contract dat we hoe dan ook nodig hebben. Liever expliciet en getoetst dan verstopt in de transformatiemotor van een leverancier.
Bezwaar 2: terugschrijven willen we niet
Het tweede bezwaar gaat over de koppeling: jullie eisen een native bidirectionele koppeling, met het terugschrijven van de fysieke laag naar het logische model. Dat willen we juist niet. Terugschrijven is verliesgevend en principieel onjuist: het model is de bron, niet de afgeleide. We genereren daarom één kant op (van model naar database) en verbieden wijziging aan de andere kant. De herleidbaarheid borgen we met de richting, niet met reconstructie achteraf. De bidirectionaliteit die we wél willen is een andere: het model en de herkomst stromen samen in de catalogus, zodat we end-to-end zicht houden.
Bezwaar 3: betaal je voor een tekentool?
Het derde bezwaar gaat over de waarde: met alle controles in de CI/CD betaal je voor een tekentool. Dat is onjuist. De waarde van de modelleertool zit in het conceptuele en logische gezag, in de generatie van de fysieke structuur en in de koppeling van begrip naar gegevenstype naar fysieke kolom. De gegevenskwaliteit en de transformatiecorrectheid horen elders, in de CI/CD. Het zijn andere controles op een andere plek, geen dubbele betaling.
We voorkomen drift op het fysieke niveau
De scherpste kritiek komt van twee kanten
De scherpste kritiek komt van twee kanten tegelijk. De modelleur ziet de herleidbaarheid verdwijnen zodra iemand de structuur rechtstreeks op het fysieke niveau wijzigt, buiten het model om. De engineer wijst op de reden dat dit gebeurt: de gegenereerde DDL zegt niets over indexen, partities, distributiesleutels en materialisatie. Juist die past hij aan om het systeem werkbaar te houden. Allebei hebben gelijk. We bedienen ze met één regime van vier afspraken.
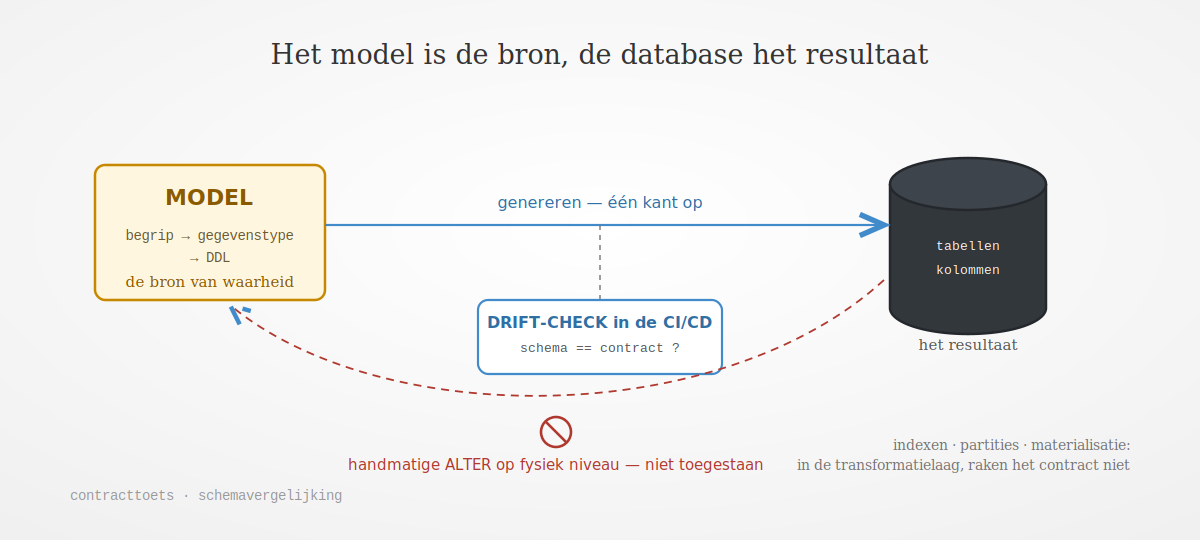
Afspraak 1: het model is de bron, één richting
We maken het model de bron en de database het resultaat. De fysieke structuur genereren we uit het model. Een rechtstreekse wijziging in de database (een handmatige ALTER, een snelle productie-fix) of een structuurwijziging in de transformatielaag buiten het model om staan we niet toe. De richting ligt vast, van model naar database, zodat de herleidbaarheid een eigenschap van het proces wordt en niet van goede bedoelingen. Die richting geldt voor de hele ladder: het fysieke model leiden we af van het logische, het logische van het conceptuele, het conceptuele van de wet of het beleid dat de basis vormt. Nooit andersom. De enige uitzondering is archeologie: bij een bestaande bron zonder logisch model ontleden we de fysieke laag eenmalig terug om een eerste versie te krijgen. Ook dan is dat een startpunt, geen werkwijze; daarna geldt opnieuw de voorwaartse richting.
Afspraak 2: optimalisatie raakt het contract niet
We scheiden de structuur van de opslagoptimalisatie. Bijna altijd is prestatie de reden dat de fysieke laag in de praktijk verschuift. Indexen, partities, distributiesleutels en materialisatie horen bij de engineer en staan in de configuratie van de transformatielaag, zonder de structuur aan te raken. Zo verdwijnt de belangrijkste aanleiding om het model op fysiek niveau te verbouwen, want de engineer optimaliseert de opslag zonder het contract te schenden.
Afspraak 3: detecteer drift, hoop er niet op
We detecteren drift in plaats van erop te hopen. Een controle in de CI/CD vergelijkt het werkelijke databaseschema met het gegenereerde contract en slaat alarm bij elke structurele afwijking. De schemacontracten vangen de drift die via de transformatielaag binnenkomt, een schemavergelijking vangt de drift die er buitenom insluipt. De modelleur ziet de afwijking dezelfde dag, niet maanden later. Onderdelen van de overheid beleggen deze taak expliciet bij de gegevensmodelleur, die de inconsistenties tussen de modellen en de implementatie signaleert.
Afspraak 4: herleidbaar tot op de betekenis
We binden de herleidbaarheid aan betekenis, niet alleen aan structuur. Een kolom kan qua type kloppen en toch semantisch zijn afgedwaald. We koppelen daarom elke fysieke kolom aan het gegevenstype en het begrip in het model en in de catalogus, zoals de overheidsaanpak voor gegevenstypering voorschrijft: van begrip naar gegevenstype naar technisch datamodel. De herleidbaarheid loopt zo door tot op de betekenis. Een afwijking is dan te herkennen als een definitiekwestie of als een structuurkwestie. Waarom die betekenislaag de harde context is die de techniek moet dragen, schreven we in Zachte semantiek is keiharde context.
We wegen de voor- en nadelen af
De voordelen: focus, herleidbaarheid, governance op de juiste plek
De voordelen van de scheiding zijn aanzienlijk. De modelleur richt zich op betekenis en structuur in een tool die de business meeneemt, de engineer op robuuste transformatie als versiebeheerde code met controles in de CI/CD. Het principe is beproefd (Dijkstra, ANSI/SPARC, Kent), de praktijk bij onderdelen van de overheid laat zien dat het werkt (een aparte gegevensmodelleur, een aparte gegevensdeling via een leveringsprotocol, met een rolsplitsing die zelfs binnen het modelleren al is voorzien). De gangbare praktijk corrigeert zich inmiddels richting hetzelfde model met datacontracten. De verticale lineage borgen we in het model, de horizontale in de transformatielaag, samengebracht in de catalogus. Een lichtere modelleertool verlaagt de drempel en legt de governance op de juiste plek, namelijk in de standaard en de uitwisseling.
De nadelen zitten in de naad
De nadelen zitten in de naad. Het model en de implementatie lopen uiteen zodra we het contract niet afdwingen. Dan raakt de modelleur los van de werkelijkheid. Twee rollen brengen overdrachtskosten mee en kunnen wachttijd opleveren als we de grens als loket inrichten in plaats van als contract. De bidirectionaliteit van de catalogus is een claim die kan tegenvallen, met een herkomstgat als gevolg. Het paradigma van de transformatielaag botst met het uitgangspunt van gegevens bij de bron, zodat we zonder scope-afspraak onnodige kopieën bouwen.
Het antwoord: splits de rollen en maak het fysieke model een contract
Het antwoord: scheiden, zo zuiver mogelijk
Terug naar de vraag waarmee we begonnen, over het scheiden van modelleren en transformeren en de zuiverheid daarvan. Het antwoord is: scheiden, zo zuiver mogelijk. Splits de modelleur en de engineer en houd het verplaatsen van gegevens uit de modelleertool. De scheiding is geen voorkeur maar een principe: Dijkstra noemde het de enige werkbare manier om het denken te ordenen, ANSI/SPARC goot het in de drie-schema-architectuur en Kent liet zien dat wie de techniek vóór de betekenis zet het verkeerde modelleert (Data and Reality, paragraaf 7.3). Onderdelen van de overheid hebben dat principe verankerd: hun aanpak scheidt de modelleerladder van het verwerkingsdomein, belegt het modelleren in een aparte rol die de begrippen nog van de logische uitwerking scheidt en regelt de verplaatsing in een eigen instrument. De overheidsbrede standaard MIM levert het metamodel waarop we de modelleerladder bouwen. Het bedrijfsleven kiest met de analytics engineer voor het gemak en levert daarmee de zuivere scheiding in; het keert nu via datacontracten terug.
De verantwoordelijkheden zijn niet vaag te houden
De verantwoordelijkheden zijn daarbij niet vaag te houden. Een data-engineer heeft niets te zoeken in het datamodel. Een modelleur heeft niets te zoeken in de transformatie. De modelleur bezit de betekenis en de structuur, van begrip tot kolom. De engineer bezit de beweging en de opslag, van bron tot rapport. Het contract is de enige plek waar de twee elkaar raken. Of dat twee personen zijn of één persoon die beide rollen vervult, hangt af van de schaal van de organisatie. De rollen mogen alleen nooit door elkaar lopen. Wie die grens laat vervagen, haalt precies de drift terug die we wilden uitbannen.
Het staat of valt met het contract in de CI/CD
De scheiding slaagt of faalt op één punt. We maken het fysieke model een afdwingbaar datacontract in de CI/CD, getoetst bij elke build van de transformatielaag (de schemacontracten uit moderne transformatieframeworks leveren daar het kant-en-klare mechanisme voor). We genereren die fysieke laag één kant op en bewaken drift met een schemavergelijking, zodat de herleidbaarheid van conceptueel tot fysiek een eigenschap van het proces blijft. Doen we dat niet, dan vervangen we één overbelaste rol door twee losgekoppelde waarheden. Dan is de modelleur straks de laatste die hoort dat de werkelijkheid is veranderd. Onderdelen van de overheid dwingen die verbinding af met een expliciete signaleringstaak voor de modelleur en met een protocol per levering. Het bedrijfsleven heeft daarvoor een scherper instrument beschikbaar: de geautomatiseerde contracttoets in de CI/CD. We zouden dat instrument gebruiken en de scoping van de transformatielaag tot de analytische laag als harde afspraak vastleggen.
We stellen eisen aan de stack, niet aan een merk
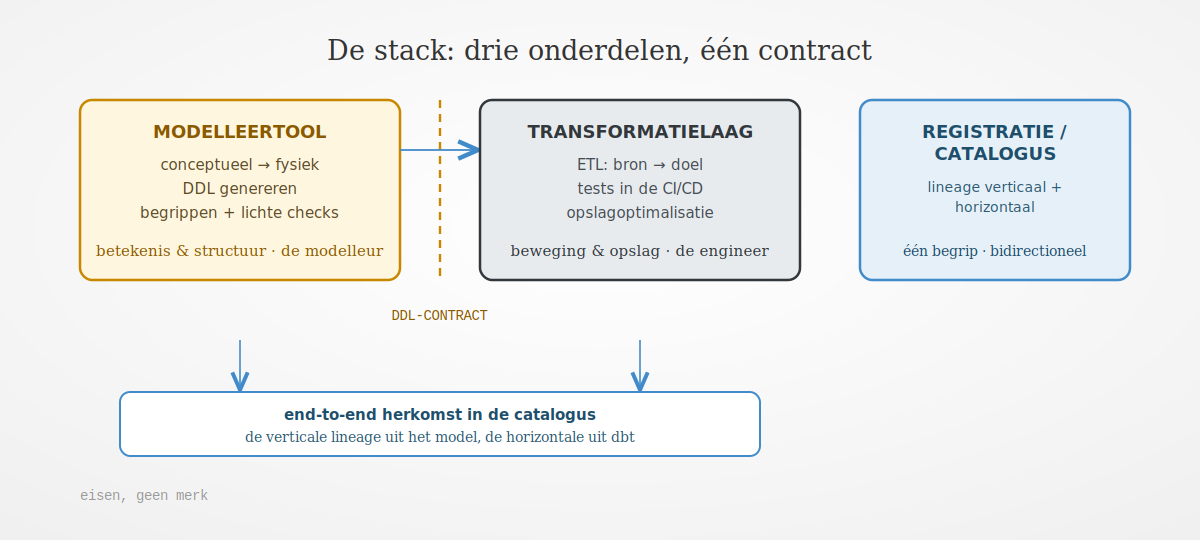
Eisen, geen merk
Het antwoord wijst geen product aan. Dat is een bewuste keuze. Het is dezelfde keuze die onderdelen van de overheid maken: de tool blijft vrij, de governance ligt in de standaard en de uitwisseling. Een merk veroudert, een eis blijft. We houden daarbij bewust lage technologische intimiteit: we bouwen de architectuur op eisen en standaarden, niet op een product. We formuleren daarom eisen aan drie onderdelen en aan het geheel. De stack valt uiteen in een modelleertool, een transformatielaag en een registratie of catalogus.
Eisen aan de modelleertool
Aan de modelleertool stellen we dat die de vier invalshoeken in één samenhangend model dekt, van semantisch en conceptueel tot logisch en technisch. Het conceptuele niveau is leesbaar voor de business zonder opleiding. De tool genereert de DDL uit het fysieke model in plaats van die met de hand te onderhouden. De tool exporteert het model in een open, MIM-conform formaat, zodat het model herbruikbaar blijft en niet aan de leverancier vastzit. De tool bindt bovendien elke fysieke kolom aan een begrip en een gegevenstype, zodat de verticale herleidbaarheid tot op de betekenis loopt. De controles in de tool blijven licht: naamgeving, datatypen, verplichte eigenschappen en hergebruik van begrippen.
Elk niveau eigen concerns, de koppeling blijvend
De drie niveaus binnen het modelleren vragen elk om eigen aandacht. Op het conceptuele niveau beheren we betekenis en de afstemming met de business. Op het logische niveau beheren we structuur, gegevenstypen en normalisatie. Op het fysieke niveau beheren we opslag en prestatie. Het hoeft daarom niet één tool te zijn. Wat wel moet, is dat de koppeling tussen de niveaus blijvend is: geen eenmalige export, maar een onderhouden verbinding die meebeweegt zodra een niveau verandert. Het fysieke model houdt bovendien een een-op-een-relatie met het conceptuele model, zodat elke tabel en elke kolom herleidbaar blijft tot een begrip en geen enkel begrip onderweg verdwijnt.
Eisen aan de transformatielaag
Aan de transformatielaag stellen we dat die de transformatie als versiebeheerde code behandelt, getoetst in de CI/CD. De laag dwingt het schema af als contract bij elke build en faalt bij een afwijking. De laag scheidt de structuur van de opslagoptimalisatie, zodat indexen, partities en materialisatie het contract niet raken. De laag levert daarnaast de horizontale lineage machineleesbaar op, zodat een catalogus die kan opnemen.
Eisen aan de catalogus
Aan de registratie stellen we dat die de verticale en de horizontale lineage samenbrengt tot herkomst van begrip tot kolom tot rapport. De koppeling is toetsbaar in beide richtingen, geen black box. De registratie is de bron van begrippen, zodat we een begrip één keer vastleggen in plaats van overal opnieuw.
Eisen aan het geheel
Aan het geheel stellen we één richting van waarheid, van model naar database, met een drift-check in de CI/CD die een wijziging buiten het model om dezelfde dag zichtbaar maakt. Zo houden we de entropie buiten de deur, de wildgroei en versnippering van gegevens die een data-architectuur het meest bedreigt. De rollen zijn gescheiden, met het contract als enige naad. Open standaarden en exporteerbaarheid gaan voor een gesloten vendor-integratie. Wie aan deze eisen voldoet, kan modelleren en transformeren zuiver scheiden, ongeacht welke producten uiteindelijk de stack vormen.
Verder lezen op valorix.nl
- De blauwdruk van je organisatie staat gewoon in de wet, over waarom de wettelijke taak het ontwerp van een organisatie en haar gegevens bepaalt.
- Zachte semantiek is keiharde context, over waarom de betekenis van gegevens de context is die de techniek moet dragen.
Bronnen
- E.W. Dijkstra, On the role of scientific thought (EWD447, 1974), opgenomen in Selected Writings on Computing: A Personal Perspective (1982). https://www.cs.utexas.edu/~EWD/transcriptions/EWD04xx/EWD447.html
- ANSI/X3/SPARC Study Group on Data Base Management Systems, drie-schema-architectuur (extern, conceptueel, intern), 1975.
- William Kent, Data and Reality (tweede editie, 2000): hoofdstuk 1 (p. 1-2), paragraaf 2.2.2 (p. 30), paragraaf 3.8 (p. 64) en paragraaf 7.3 (p. 111).
- MIM, Metamodel Informatiemodellering: overheidsbrede standaard, beheerd door Geonovum en geborgd via Forum Standaardisatie. https://docs.geostandaarden.nl/mim/mim/ en https://www.forumstandaardisatie.nl
- Aanpak bij onderdelen van de Nederlandse overheid voor gegevenstypering, gegevensdeling en de inrichting van gegevensmanagement (vier invalshoeken, rolverdeling modelleur en engineer, levering per protocol).
- Anouschka Ausems, John Bulles en Mariette Lokin, Wetsanalyse: voor een werkbare uitvoering van wetgeving met ICT (Boom, Open Access).
- State of Analytics Engineering, branche-onderzoek (2024 en 2025). https://www.getdbt.com/resources/state-of-analytics-engineering-2024 en https://www.getdbt.com/blog/state-of-analytics-engineering-2025-summary
- Towards Data Science, Data Modeling for Analytics Engineers (over het samenvallen van logisch en fysiek in de transformatielaag). https://towardsdatascience.com/data-modeling-for-analytics-engineers-the-complete-primer/
- Schemacontracten in transformatieframeworks (sinds 2023) en datacontracten. https://docs.getdbt.com/docs/collaborate/govern/model-contracts en https://atlan.com/dbt-data-contracts/